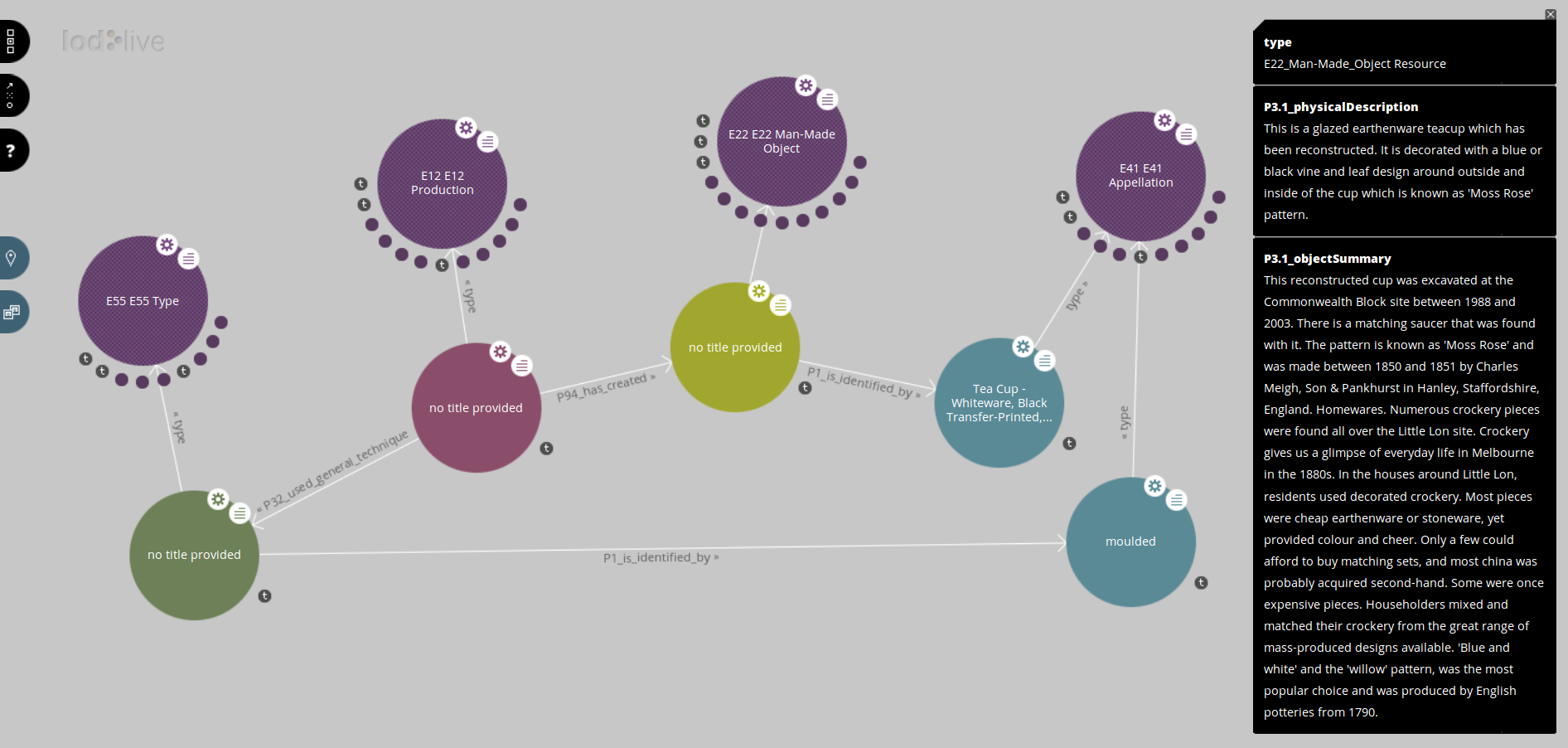
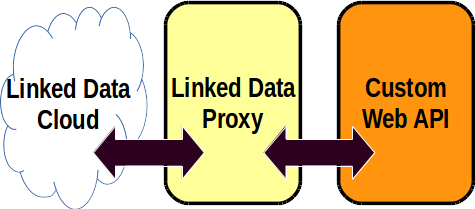
As 2016 stumbles to an end, I’ve put in a few days’ work on my new project Oceania, which is to be a Linked Data service for cultural heritage in this part of the world. Part of this project involves harvesting data from cultural institutions which make their collections available via so-called “Web APIs”. There are some very standard ways to publish data, such as OAI-PMH, OpenSearch, SRU, RSS, etc, but many cultural heritage institutions instead offer custom-built APIs that work in their own peculiar way, which means that you need to put in a certain amount of effort in learning each API and dealing with its specific requirements. So I’ve turned to the problem of how to deal with these APIs in the most generic way possible, and written a program that can handle a lot of what is common in most Web APIs, and can be easily configured to understand the specifics of particular APIs.
Continue reading A tool for Web API harvesting