The first post gave an introduction and overview of the architecture of the publication software, and the second dealt quite specifically with how names and identifiers work in the LOD publication software.
In this post I’ll cover how the publication software takes the data published by Museum Victoria’s API and reshapes it to fit a common conceptual model for museum data, the “Conceptual Reference Model” published by the documentation committee of the Internal Council of Museums. I’m not going to exhaustively describe the translation process (you can read the source code if you want the full story), but I’ll include examples to illustrate the typical issues that arise in such a translation.
The CIDOC Conceptual Reference Model
The CIDOC CRM, as it’s usually called, is a system of concepts for analysing and describing the content of museum collections. It is not intended to be a replacement for the Collection Management Systems which museums use to store their data; it is rather intended to function as a kind of lingua franca, through which content from a variety of systems can be expressed in a generally intelligible way.
The Conceptual Reference Model covers a wide range of museological concerns: items can be described in terms of their materials and mode of construction, as well as by who made them, where and when, and for what purpose.
The CRM also provides a framework to describe the events in which objects are broken into pieces, or joined to other objects, damaged or repaired, created or utterly destroyed. Objects can be described in terms of the symbolic and intellectual content which they embody, which are themselves treated as “intellectual objects”. The lineage of intellectual influence can be described, either speculatively, in a high-level way, or by explicitly tracing and documenting the influences that were known have taken place at particular times and locations. The legal history of objects can also be traced through transfer of ownership and custody, commission, sale and purchase, theft and looting, loss and discovery. Where the people involved in these histories are known, they too can be named and described and their histories interwoven with those of other people, objects, and ideas.
Core concepts and additional classification schemes
The CRM framework is quite high level. Only a fairly small number of very general types of thing are defined in the CRM; only concepts general enough to be useful for any kind of museum; whether a museum of computer games or of classical antiquity. Each of these concepts is identified by an alphanumeric code and an English-language name. In addition, the CRM framework allows for arbitrary typologies to be added on, to be used for further classifying pretty much anything. This is to allow all the terms from any classification system used in a museum to be exported directly into a CRM-based dataset, simply by describing each term as an “E55 Type". In short, the CRM consists of a fairly fixed common core, supplemented by a potentially infinite number of custom vocabularies which can be used to make fine distinctions of whatever kind are needed.
Therefore, a dataset based on the CRM will generally be directly comparable with another dataset only in terms of the core CRM-defined entities. The different classification schemes used by different datasets remain “local” vocabularies. To achieve full interoperability between datasets, these distinct typologies would additionally need to be aligned, by defining a “mapping” table which lists the equivalences or inequivalences between the terms in the two vocabularies. For instance, such a table might say that the term “moulded” used in Museum Victoria’s collection is more or less the same classification as “molding (forming)” in the Getty Art and Architecture thesaurus.
Change happens through “events”
To model how things change through time, the CRM uses the notion of an “event”. The production of a physical object, for instance, is modelled as an E12 Production event (NB concepts in the CRM are all identified by an alphanumeric code). This production event is linked to the object which it produced, as well as to the person or persons who played particular creative roles in that event. The event may also have a date and place associated with it, and may be linked to the materials and to the method used in the event.
On a somewhat philosophical note, this focus on discrete events is justified by the fact that not all of history is continuously documented, and we necessarily have a fragmentary knowledge of the history of any given object. Often a museum object will have passed through many hands, or will have been modified many times, and not all of this history is known in any detail. If we know that person A created an object for person B, and that X years later the object turned up in the hands of person C, we can’t assume that the object remained in person B’s hands all those X years. A data model which treated “ownership” as a property of an object would be liable to making such inflated claims to knowledge which is simply not there. Person C may have acquired it at any point during that period, and indeed there may have been many owners in between person B and person C. This is why it makes sense to document an object’s history in terms of the particular events which are known and attested to.
Museum Victoria’s API
How does Museum Victoria’s data fit in terms of the CIDOC model?
In general the model works pretty well for Museum Victoria, though there are also things in MV’s data which are not so easy to express in the CRM.
Items
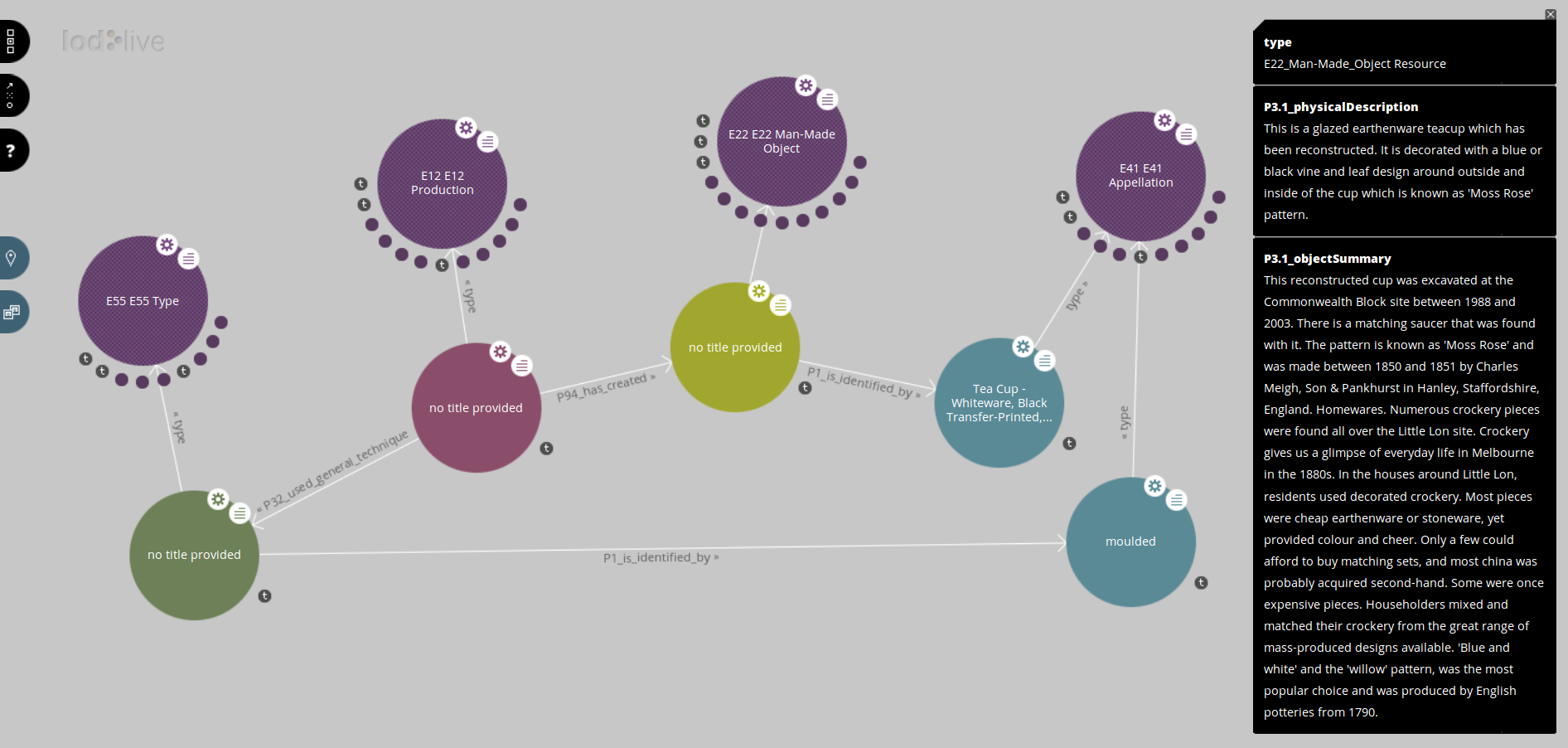
Museum Victoria describes items as “Things made and used by people”. These correspond exactly to the notion of E22 Man-Made Object in the CIDOC CRM (if you can excuse the sexist language), described as comprising “physical objects purposely created by human activity.”
Every MV item is therefore expressed as an E22 Man-Made Object.
Titles
Museum Victoria’s objects have an objectName property which is a simple piece of text; a name or title. In the CIDOC CRM, the name of an object is something more complex; it’s an entity in its own right, called an E41 Appellation. The reason why a name is treated as more than just a simple property of an object is that in the CRM, it must be possible to treat an object’s name as an historical phenomenon; after all, it will have been applied to an object by a particular person (the person who created the object, perhaps, or an archaeologist who dug it out of the ground, or a curator or historian), at some historical point in time. An object may have a number of different names, each given it by different people, and used by different people at different times.
However, because the Museum Victoria names are simple (a single label) we can ignore most of that complexity. We only need to define an E41 Appellation whose value is the name, and link the E41 Appellation to the E22 Man-Made Object using a P1 is identified by association.
Articles, Items and their relationships
The MV API provides access to a number of “articles” which are documents related to the Museum’s collection. For each article, the API shows a list of the related collection items; and for each item, you can get the corresponding list of related articles. Although the exact nature of the relationship isn’t made explicit, it’s reasonable to assume that an item is in some way documented by the articles that are related to it. In the CIDOC CRM, such an article is considered an E31 Document, and it bears a P70 documents relationship to the item which it’s about.
If the relationship between an item and article is easy to guess, there are a couple of other relationships which are a little less obvious: an article also has a list of related articles, and each item also has a list of related items. What is that nature of those relationships? In what way exactly does article X relate to article Y, or item A to item B? The MV API’s documentation doesn’t say, and it wouldn’t surprise me if the Museum’s collection management system leaves this question up to the curators’ judgement.
A bit of empirical research seemed called for. I checked a few of the related items and the examples I found seemed to fall into two categories:
- One item is a photograph depicting another item (the specific relationship here is really “depicts”)
- Two items are both photographs of the same subject (the relationship is “has the same subject as”).
Obviously there are two different kinds of relationship here in the Museum’s collection, both of them presented (through the API) in the same way. As a human, I can tell them apart, but my proxy software is not going to be able to. So I need to find a more general relationship which subsumes both the relationships above, and fortunately, the CIDOC CRM includes such a relationship, namely P130 shows features of.
This property generalises the notions of “copy of” and “similar to” into a dynamic, asymmetric relationship, where the domain expresses the derivative, if such a direction can be established.
Otherwise, the relationship is symmetric. It is a shortcut of P15 was influenced by (influenced) in a creation or production, if such a reason for the similarity can be verified. Moreover it expresses similarity in cases that can be stated between two objects only, without historical knowledge about its reasons.
For example, I have a photograph of a piece of computer hardware (which is the relatedItem), and the photo is therefore a kind of derivative of the hardware (though the Museum Victoria API doesn’t tell me which of the objects was the original and which the derivative). In another example I have two photos of the same house; here there’s a similarity which is not due to one of the photos being derived from the other.
Ideally, it would be preferable to be able to represent these kinds of relationships more precisely; for instance, in the case of the two photos of the house, one could generate a resource that denotes the actual physical house itself, and link that to the photographs, but because the underlying data doesn’t include this information in a machine-readable form, the best we can do is to say that the two photos are similar.
Production techniques
Some of the items in the Museum’s collection are recorded as having been produced using a certain “technique”. For instance, archaeological artefacts in the MV collection have a property called archeologyTechnique, which contains the name of a general technique, such as moulded, in the case of certain ceramic items.
This corresponds to the CRM concept P32 used general technique, which is described like so:
This property identifies the technique or method that was employed in an activity.
These techniques should be drawn from an external E55 Type hierarchy of consistent terminology of
general techniques or methods such as embroidery, oil-painting, carbon dating, etc.
Note that in CIDOC this “general technique” used to manufacture an object is not a property of the object iself; it’s a property of the activity which produced the object (i.e. the whole process in which the potter pressed clay into a mould, glazed the cup, and fired it in a kiln).
Note also that, for the CIDOC CRM, the production technique used in making these tea-cups is not the text string “moulded”; it is actually an abstract concept identified by a URI. The string “moulded” is just a human-readable name attached as a property of that concept. That same concept might very well have a number of other names in other languages, or even in English there’s the American variant spelling “molded”, and synonyms such as “cast” that could all be alternative names for the same concept.
Translating a Museum Victoria item with a technique into the CRM therefore involves identifying three entities:
- the object itself (an
E22 Man-Made Object); - the production of the object (an
E12 Productionactivity); - the technique used in the course of that activity to produce the object (an
E55 Typeof technique)
These three entities are then linked together:
- The production event “
P32 used general technique"of the technique; and - The production event [edit:
"P94 has created""P108 has produced"the object itself.
Notes
The items, articles, specimens and species in the Museum’s API are all already first-class objects and can be easily represented as concepts in Linked Data. The archeologyTechnique field also has a fairly restricted range of values, and each of those values (such as “moulded”) can be represented as a Linked Data concept as well. But there are a number of other fields in the Museum’s API which are in the form of relatively long pieces of descriptive text. For example, an object’s objectSummary field contains a long piece of text which describes the object in context. For example, here’s the objectSummary of one our moulded tea cups:
This reconstructed cup was excavated at the Commonwealth Block site between 1988 and 2003. There is a matching saucer that was found with it. The pattern is known as 'Moss Rose' and was made between 1850 and 1851 by Charles Meigh, Son & Pankhurst in Hanley, Staffordshire, England.
Homewares.
Numerous crockery pieces were found all over the Little Lon site. Crockery gives us a glimpse of everyday life in Melbourne in the 1880s. In the houses around Little Lon, residents used decorated crockery. Most pieces were cheap earthenware or stoneware, yet provided colour and cheer. Only a few could afford to buy matching sets, and most china was probably acquired second-hand. Some were once expensive pieces. Householders mixed and matched their crockery from the great range of mass-produced designs available. 'Blue and white' and the 'willow' pattern, was the most popular choice and was produced by English potteries from 1790.
It’s not quite as long as an “article” but it’s not far off it. Another textual property is called physicalDescription, and has a narrower focus on the physical nature of the item:
This is a glazed earthenware teacup which has been reconstructed. It is decorated with a blue or black vine and leaf design around outside and inside of the cup which is known as 'Moss Rose' pattern.
The CIDOC CRM does include concepts related to the historical context and the physical nature of items, but it’s not at all easy to extract that detailed information from the descriptive prose of these, and similar fields. Because the information is stored in a long narrative form, it can’t be easily mapped to the denser data structure of a Linked Data graph. The best we can hope to do with these fields is to treat them as notes attached to the item.
The CIDOC CRM includes a concept for attaching a note: P3 has note. But to represent these two different types of note, it’s necessary to extend the CRM by creating two new, specialized versions (“sub-properties”) of the property called P3 has note, which I’ve called P3.1 objectSummary and P3.1 physicalDescription.
Summary
It’s possible to recognise three distinct patterns in mapping an API such as Museum Victoria’s to a Linked Data model like the CIDOC CRM.
- Where the API provides access to a set of complex data objects of a particular type, these can
be mapped straight-forwardly to a corresponding class of Linked Data resources (e.g. the items, species, specimens, and articles in MV’s API). - Where the API exposes a simple data property, it can be straightforwardly converted to a Linked Data property (e.g. the two types of notes, in the example above).
- Where the API exposes a simple data property whose values come from a fairly limited range (a “vocabulary”), then those individual property values can be assigned identifiers of their own, and effectively promoted from simple data properties to full-blown object properties (e.g. the production techniques in Museum Victoria’s API).
Conclusion
It’s been an interesting experiment, to generate Linked Open Data from an open API using a simple proxy: I think it shows that the technique is a very viable mechanism for institutions to break into the LOD cloud and contribute their collection in a standardised manner, without necessarily having to make any changes to their existing systems or invest in substantial software development work. To my mind, making that first step is a significant barrier that holds institutions and individuals back from realising the potential in their data. Once you have a system for publishing LOD, you are opening up a world of possibilities for external developers, data aggregators, and humanities researchers, and if your data is of interest to those external groups, you have the possibility of generating some significant returns on your investment, and the possibility of “harvesting” some of that work back into your institution’s own web presence in the form of better visualizations, discovery interfaces, and better understanding of your own collection.
Before the end of the year I hope to explore some further possibilities in the area of user interfaces based on Linked Data, to show some of the value that these Linked Data publishing systems can support.
Hi Conal! A great piece but some corrections on the CRM modeling:
1. Use as specific class as possible. Eg for artworks: E35_Title rather than E41_Appellation
2. Be careful about domain & range. Eg E12_Production P108_has_produced , not P94_has_created
3. P130_shows_features_of is wrong, should be P62_depicts
Re “related objects”: unfortunately CRM doesn’t have a notion of “general relation” between objects.
In Getty CONA I break relations into several groups (CRM Cases), eg Same P16_used_specific_object, P16_used_specific_object, E81_Transformation, P130i_features_are_also_found_on, P62_depicts, Same P46i_forms_part_of
Sorry, this forum kills text between angle brackets, so the above is unreadable. Here it is again with quotes:
Hi Conal! A great piece but some corrections on the CRM modeling:
1. Use as specific class as possible. Eg for artworks: E35_Title rather than E41_Appellation
2. Be careful about domain & range. Eg E12_Production P108_has_produced “object”, not P94_has_created
3. “photo” P130_shows_features_of “object” is wrong, should be P62_depicts
Re “related objects”: unfortunately CRM doesn’t have a notion of “general relation” between objects.
In Getty CONA I break relations into several groups (CRM Cases), eg Same P16_used_specific_object, P16_used_specific_object, E81_Transformation, P130i_features_are_also_found_on, P62_depicts, Same P46i_forms_part_of …
Thanks Vladimir!
And thanks for your comments on the CRM modelling; they are much appreciated.
To answer your numbered points:
1. Unfortunately the museum’s API doesn’t offer me “artworks” with “titles” – only “objects” (which may or may not be artworks). I have used the more general property because although a more specific property is better for artworks, I don’t have an automated means to determine whether they were in fact artworks, and not e.g. horseshoes or chamber-pots. That’s why I chose to do it that way, at least, though it’s possible I’ve missed some clues provided by the API that would enable me to use a more precise class. When I get a chance I would like to go back and refine the model, but this is just a “proof of concept” (Museum Victoria are not a paying client) so I haven’t felt much of a call to bring it to a “production” level of readiness. I think if it were a real project, some of these modelling issues would be best addressed by improving their underlying API; I know for a fact that in some places the underlying data in their CMS is richer than the API exposes (i.e. the API itself is a semantic bottleneck).
2. A definite bug – thank you! I have logged an issue and I will fix it shortly. https://github.com/Conal-Tuohy/XProc-Z/issues/13
3. The problem here again (I had hoped to make it clear in the section entitled “Articles, Items and their relationships”) is that the museum’s API is not specific enough about the objects to allow the XSLT to make the assertion that a photo depicts another object. It’s easy enough for a human to tell, by reading the textual description, that this is a photo of a house, and that this other object is a photo of the same house, but those facts are not expressed in a machine-actionable way. All I have to go on is that some objects are “related”. Hence I’ve felt constrained to assert something much vaguer than the notion of “depiction”, namely that the objects are merely similar, using P130_shows_features_of. I feel a bit uncomfortable even with that, given that it’s only based on an assertion by the museum’s API that the objects are “related”. However, from the example cases I looked at, it certainly seemed to be the case that “related” objects showed some similarity. When you say that using P130_shows_features_of is “wrong”, do you just mean that it is overly general (which I would accept it is, of necessity), or are you saying that it’s actually false to fact? If the latter, could you explain why you think that?
1. P102_has_title has Domain: E71 Man-Made Thing. So it doesn’t matter if they are paintings or horseshoes.
3. P130_shows_features_of is not vaguer than P62_depicts. P130 means “a derivation” or “copy after” etc etc. It’s used for artistic derived works, not for photos. Scope note says “It is a short-cut of P15 was influenced by in a creation or production”: which means “the production of the photo was Influenced by the original object”, but Influenced is too weak interpretation for this situation.
Furthermore, I think you said some instances could be “a document about the original object” and similar, in which case there’s are no “shared features” at all.
If the relations are directed (X is later object –related to–> Y is the original object), you have this option:
X P128_carries X-concept.
X-concept a E73_Information_Object;
P67_refers_to Y.
P67_refers_to is a weak relation that commits neither to strong aboutness (P129 is about), nor to visual representation (depiction)
Surely “horseshoe” is not the title of a horseshoe? Horseshoes do not have titles (OK perhaps Marchel Duchamp might have entitled a horseshoe, but in general, the names of such objects are not titles but generic names).
I’m very interested to read your interpretation of P130_shows_features_of, Vladimir. I certainly agree that’s one valid interpretation, but to me, the scope note implies that there are other (broader) semantics which would apply in other circumstances. In those other cases, P130_shows_features_of can’t, it seems to me, be interpreted as a shortcut for a (directed) statement about copying or derivation. I’ve highlighted the bits which are relevant to that interpretation, in the scope note.
“This property generalises the notions of “copy of” and “similar to” into a dynamic, asymmetric relationship, where the domain expresses the derivative, if such a direction can be established. Otherwise, the relationship is symmetric. It is a short-cut of P15 was influenced by (influenced) in a creation or production, if such a reason for the similarity can be verified. Moreover it expresses similarity in cases that can be stated between two objects only, without historical knowledge about its reasons.”
How else should those bold sections be interpreted?