Tonight I’m knocking back a gin and tonic to celebrate finishing a piece of software development for my client the Public Record Office Victoria; the archives of the government of the Australian state of Victoria.
The work, which will go live in a couple of weeks, was an update to a browser-based visualization tool which we first set up last year. In response to user testing, we made some changes to improve the visualization’s usability. It certainly looks a lot clearer than it did, and the addition of some online help makes it a bit more accessible for first-time users.
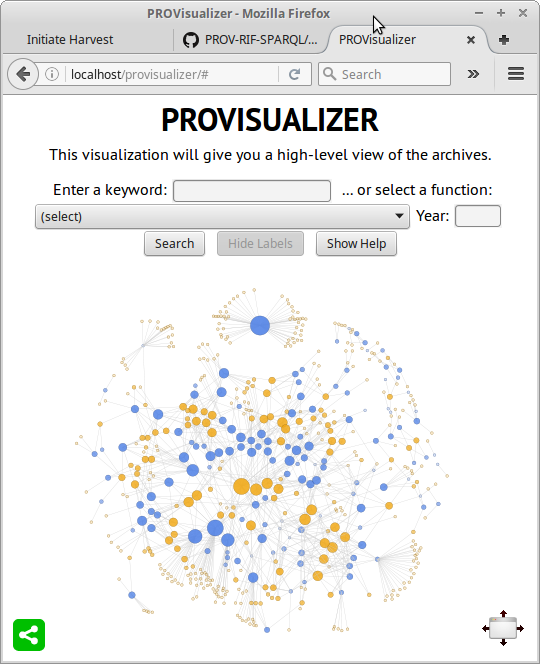
The visualization now looks like this (here showing the entire dataset, unfiltered, which is not actually that useful, though it is quite pretty):
Continue reading Visualizing Government Archives through Linked Data