The first post gave an introduction and overview of the architecture of the publication software, and the second dealt quite specifically with how names and identifiers work in the LOD publication software.
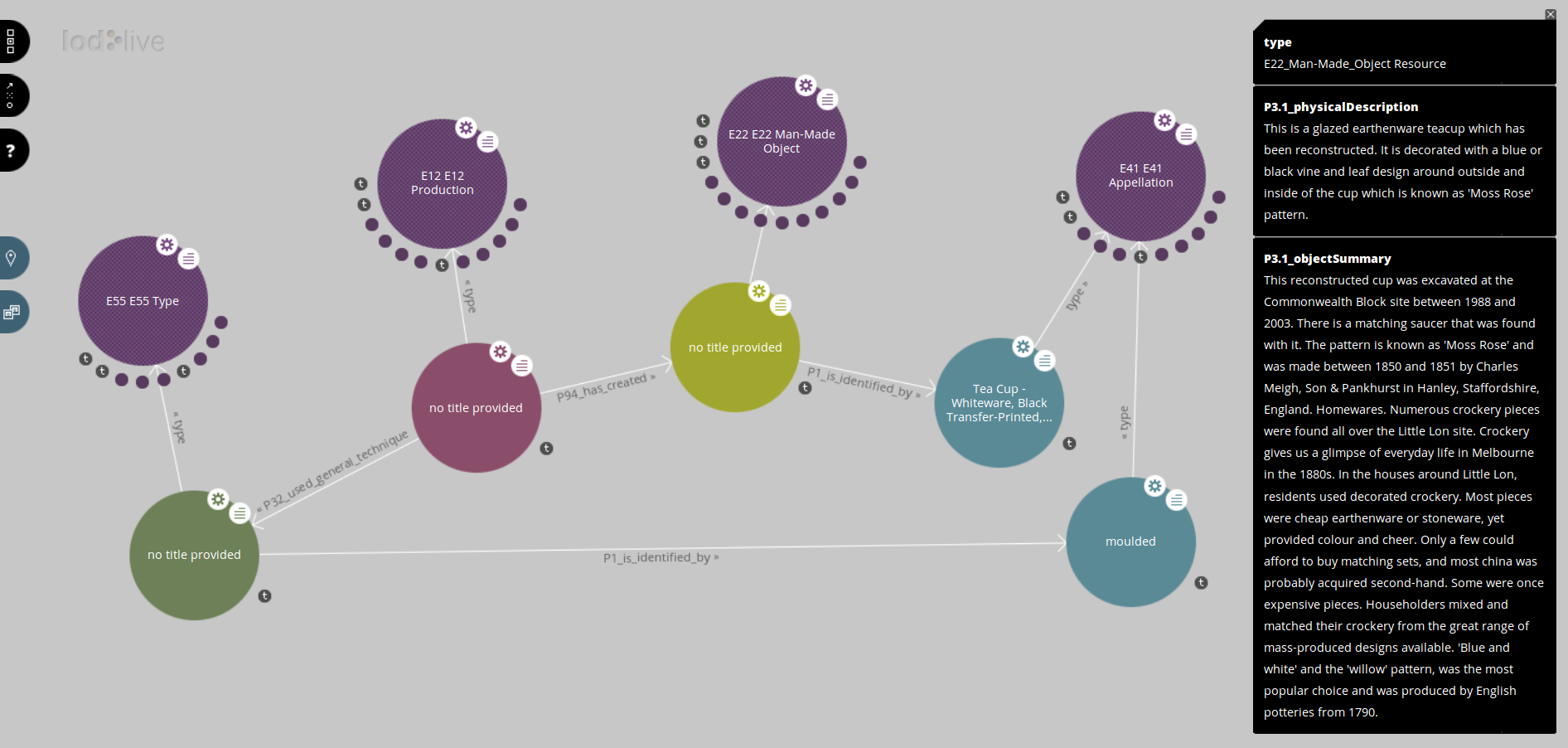
In this post I’ll cover how the publication software takes the data published by Museum Victoria’s API and reshapes it to fit a common conceptual model for museum data, the “Conceptual Reference Model” published by the documentation committee of the Internal Council of Museums. I’m not going to exhaustively describe the translation process (you can read the source code if you want the full story), but I’ll include examples to illustrate the typical issues that arise in such a translation.