Notes for my Open Repositories 2017 conference presentation. I will edit this post later to flesh it out into a proper blog post.
Follow along at: conaltuohy.com/blog/analysis-policy-online/
Continue reading Analysis & Policy Online
Tag: LODLAM
Oceania
I am really excited to have begun my latest project: a Linked Open Data service for online cultural heritage from New Zealand and Australia, and eventually, I hope, from our other neighbours. I have called the service “oceania.digital”
The big idea of oceania.digital is to pull together threads from a number of different “cultural” data sources and weave them together into a single web of data which people can use to tell a huge number of stories.
There are a number of different aspects to the project, and a corresponding number of stages to go through… Continue reading Oceania
Australian Society of Archivists 2016 conference #asalinks
Last week I participated in the 2016 conference of the Australian Society of Archivists, in Parramatta.

I was very impressed by the programme and the discussion. I thought I’d jot down a few notes here about just a few of the presentations that were most closely related to my own work. The presentations were all recorded, and as the ASA’s YouTube channel is updated with newly edited videos, I’ll be editing this post to include those videos.
Continue reading Australian Society of Archivists 2016 conference #asalinks
Linked Open Data Visualisation at #GLAMVR16
On Thursday last week I flew to Perth, in Western Australia, to speak at an event at Curtin University on visualisation of cultural heritage. Erik Champion, Professor of Cultural Visualisation, who organised the event, had asked me to talk about digital heritage collections and Linked Open Data (“LOD”).
The one-day event was entitled “GLAM VR: talks on Digital heritage, scholarly making & experiential media”, and combined presentations and workshops on cultural heritage data (GLAM = Galleries, Libraries, Archives, and Museums) with advanced visualisation technology (VR = Virtual Reality).
The venue was the Curtin HIVE (Hub for Immersive Visualisation and eResearch); a really impressive visualisation facility at Curtin University, with huge screens and panoramic and 3d displays.
There were about 50 people in attendance, and there would have been over a dozen different presenters, covering a lot of different topics, though with common threads linking them together. I really enjoyed the experience, and learned a lot. I won’t go into the detail of the other presentations, here, but quite a few people were live-tweeting, and I’ve collected most of the Twitter stream from the day into a Storify story, which is well worth a read and following up.
Continue reading Linked Open Data Visualisation at #GLAMVR16
Visualizing Government Archives through Linked Data
Tonight I’m knocking back a gin and tonic to celebrate finishing a piece of software development for my client the Public Record Office Victoria; the archives of the government of the Australian state of Victoria.
The work, which will go live in a couple of weeks, was an update to a browser-based visualization tool which we first set up last year. In response to user testing, we made some changes to improve the visualization’s usability. It certainly looks a lot clearer than it did, and the addition of some online help makes it a bit more accessible for first-time users.
The visualization now looks like this (here showing the entire dataset, unfiltered, which is not actually that useful, though it is quite pretty):
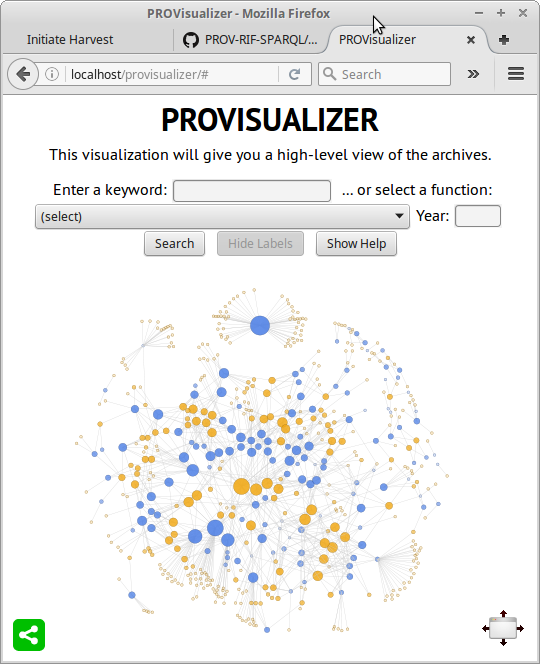
Continue reading Visualizing Government Archives through Linked Data
Taking control of an uncontrolled vocabulary
A couple of days ago, Dan McCreary tweeted:
Working on new ideas for NoSQL metadata management for a talk next week. Focus on #NoSQL, Documents, Graphs and #SKOS. Any suggestions?
— Dan McCreary (@dmccreary) November 14, 2015
It reminded me of some work I had done a couple of years ago for a project which was at the time based on Linked Data, but which later switched away from that platform, leaving various bits of RDF-based work orphaned.
One particular piece which sprung to mind was a tool for dealing with vocabularies. Whether it’s useful for Dan’s talk I don’t know, but I thought I would dig it out and blog a little about it in case it’s of interest more generally to people working in Linked Open Data in Libraries, Archives and Museums (LODLAM).
Continue reading Taking control of an uncontrolled vocabulary
Bridging the conceptual gap: Museum Victoria’s collections API and the CIDOC Conceptual Reference Model
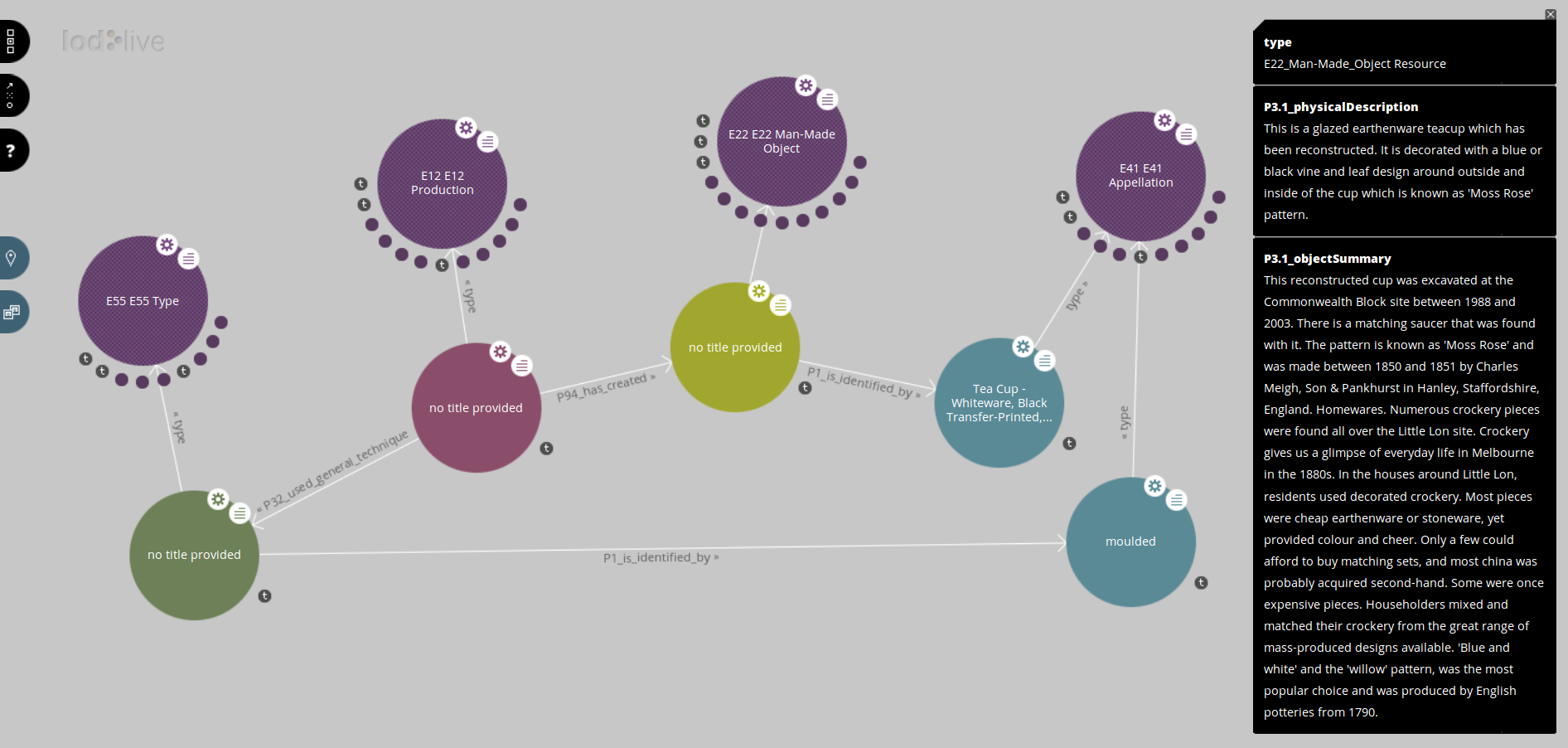
The first post gave an introduction and overview of the architecture of the publication software, and the second dealt quite specifically with how names and identifiers work in the LOD publication software.
In this post I’ll cover how the publication software takes the data published by Museum Victoria’s API and reshapes it to fit a common conceptual model for museum data, the “Conceptual Reference Model” published by the documentation committee of the Internal Council of Museums. I’m not going to exhaustively describe the translation process (you can read the source code if you want the full story), but I’ll include examples to illustrate the typical issues that arise in such a translation.
Names in the Museum
My last blog post described an experimental Linked Open Data service I created, underpinned by Museum Victoria’s collection API. Mainly, I described the LOD service’s general framework, and explained how it worked in terms of data flow.
To recap briefly, the LOD service receives a request from a browser and in turn translates that request into one or more requests to the Museum Victoria API, interprets the result in terms of the CIDOC CRM, and returns the result to the browser. The LOD service does not have any data storage of its own; it’s purely an intermediary or proxy, like one of those real-time interpreters at the United Nations. I call this technique a “Linked Data proxy”.
I have a couple more blog posts to write about the experience. In this post, I’m going to write about how the Linked Data proxy deals with the issue of naming the various things which the Museum’s database contains.
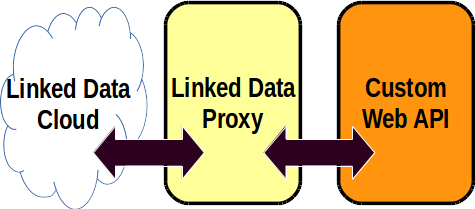
Linked Open Data built from a custom web API
I’ve spent a bit of time just recently poking at the new Web API of Museum Victoria Collections, and making a Linked Open Data service based on their API.
I’m writing this up as an example of one way — a relatively easy way — to publish Linked Data off the back of some existing API. I hope that some other libraries, archives, and museums with their own API will adopt this approach and start publishing their data in a standard Linked Data style, so it can be linked up with the wider web of data.
Continue reading Linked Open Data built from a custom web API
Proxying: a trick to easily add features to existing websites and applications
At the start of last month I attended the LODLAM (Linked Open Data in Libraries, Archives and Museums) Summit in Sydney, in the lovely Mitchell Library of the State Library of New South Wales.
The Summit is organised as an “un-conference”. There is no pre-defined agenda; it’s organised by the participants themselves at the start of the day. It makes it a very participatory event; your brain is in top gear the whole time and everything is so interesting you end up feeling a bit stunned at the end of the day.
One of the features of the Summit was a series of very brief talks (“speedos”) on a variety of topics. At the last minute I decided I’d contribute a quick rant on a particular hobby-horse of mine: the value of using proxies to build web applications, Linked Open Data, and so on. Continue reading Proxying: a trick to easily add features to existing websites and applications