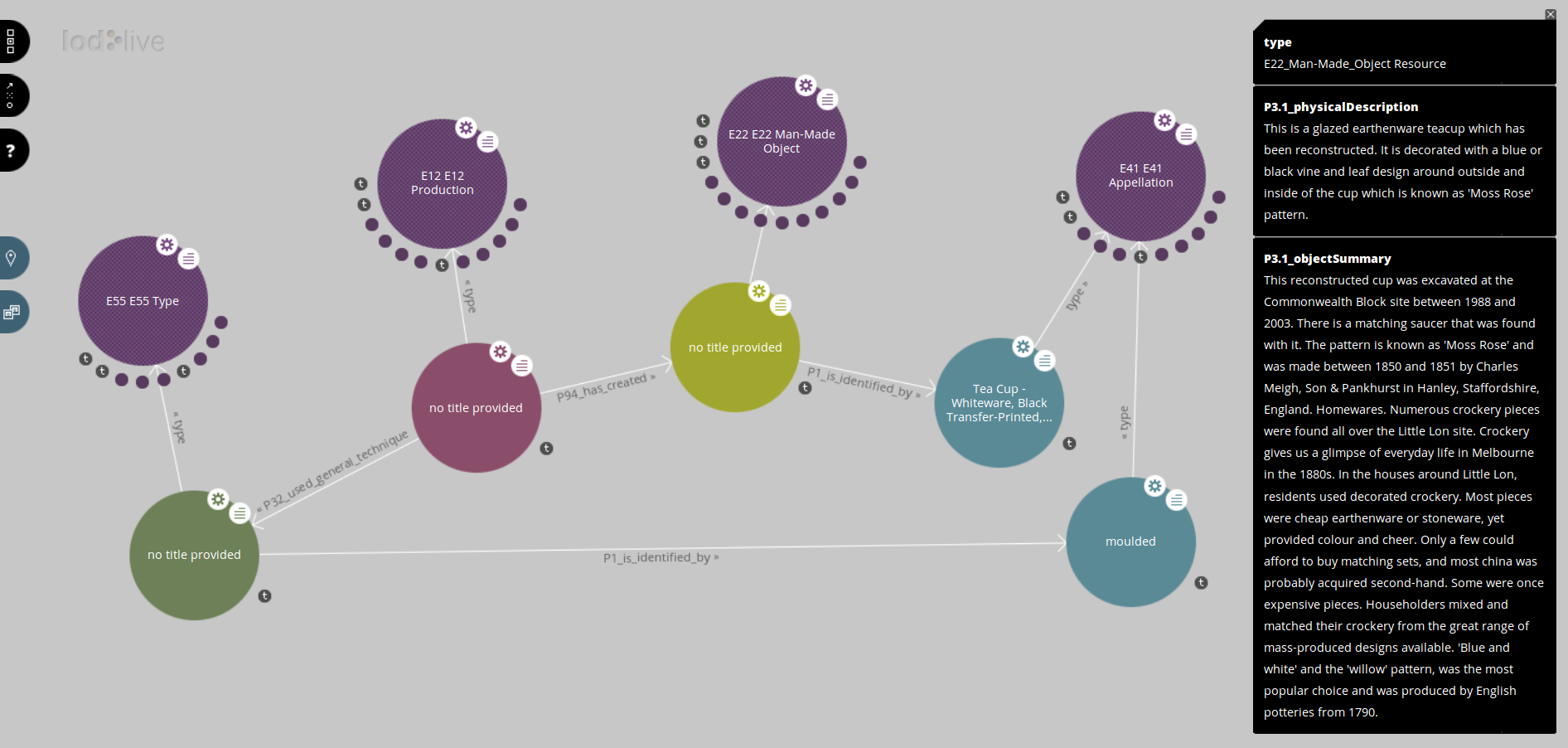
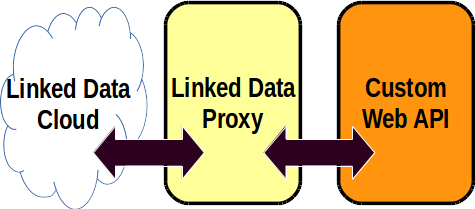
Last week I participated in the 2016 conference of the Australian Society of Archivists, in Parramatta.

I was very impressed by the programme and the discussion. I thought I’d jot down a few notes here about just a few of the presentations that were most closely related to my own work. The presentations were all recorded, and as the ASA’s YouTube channel is updated with newly edited videos, I’ll be editing this post to include those videos.
Continue reading Australian Society of Archivists 2016 conference #asalinks