I’ve spent a bit of time just recently poking at the new Web API of Museum Victoria Collections, and making a Linked Open Data service based on their API.
I’m writing this up as an example of one way — a relatively easy way — to publish Linked Data off the back of some existing API. I hope that some other libraries, archives, and museums with their own API will adopt this approach and start publishing their data in a standard Linked Data style, so it can be linked up with the wider web of data.
Two ways to skin a cat
There are two basic ways you can take an existing API and turn it into a Linked Data service.
One way is the “metadata aggregator” approach. In this approach, an “aggregator” periodically downloads (or “harvests”) the data from the API, in bulk, converts it all into RDF, and stores it in a triple-store. Then another application — a Linked Data publishing service — can read that aggregated data from the triple store using a SPARQL query and expose it in Linked Data form. The tricky part here is that you have to create and maintain your own copy (a cache) of all the data which the API provides. You run the risk that if the source data changes, then your cache is out of date. You need to schedule regular harvests to be sure that the copy you have is as up to date as you need it to be. You have to hope that the API can tell you which particular records have changed or been deleted, otherwise, you may have to download every piece of data just to be sure.
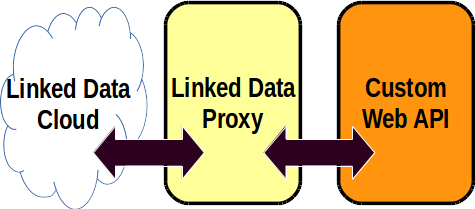
But this blog post is about another way which is much simpler: the “proxy” approach. A Linked Data proxy is a web application that receives a request for Linked Data, and in order to satisfy that request, makes one or more requests of its own to the API, processing the results it receives, and formatting them as Linked Data, which it then returns. The advantage of this approach is that every response to a request for Linked Data is freshly prepared. There is no need to maintain a cache of the data. There is no need for harvesting or scheduling. It’s simply a translator that sits in front of the API and translates what it says into Linked Data.
This is an approach I’ve been meaning to try out for a fair while, and in fact I gave a very brief presentation on the proxy idea at the recent LODLAM Summit in Sydney. All I needed was a good API to try it out with.
Museum Victoria Collection API
The Museum Victoria Collection API was announced on Twitter by Ely Wallis on August 25th:
The cat's out of the bag – @museumvictoria has a new collections online. We hope you like it! http://t.co/c0oNTWDk5t
— Ely Wallis (@elyw) August 25, 2015
Well as it happened I did like it, so I got in touch. Since it’s so new, the API’s documentation is a bit sparse, but I did get some helpful advice from the author of the API, Museum Victoria’s own Michael Mason, including details of how to perform searches, and useful hints about the data structures which the API provides.
In a nutshell, the Museum Victoria API provides access to data about four different sorts of things:
- Items (artefacts in the Museum’s collections),
- Specimens (biological specimens),
- Species (which the specimens belong to), and
- Articles (which document the other things)
There’s also a search API with which you can search within all of those categories.
Armed with this knowledge, I used my trusty XProc-Z proxy software to build a Linked Data proxy to that API.
Linked Data
Linked Data is a technique for publishing information on the web in a common, machine-understandable way.
The central principle of Linked Data is that all items of interest are identified with an HTTP URI (“Uniform Resource Identifier”). And “Resource” here doesn’t just mean web pages or other electronic resources; anything at all can be a “Resource”: people, physical objects, species of animal, days of the week … anything. If you take one of these URIs and put it into your browser, it will deliver you up some information which relates to the thing identified by the URI.
Because of course you can’t download a person or a species of animal, there is a special trick to this: if you send a request for a URI which identifies one of these “non-information resources”, such as a person, the server can’t simply respond by sending you an information resource (after all, you asked for a person, not a document). Instead it responds by saying “see also” and referring you to a different URL. This is basically saying “since you can’t download the resource you asked for (because it’s not an information resource), here is the URL of an information resource which is relevant to your request”. Then when your browser makes a request from that second URL, it receives an information resource. This is why, when browsing Linked Data, you will sometimes see the URI in your browser’s address bar change: first it makes a request for one URI and then is automatically redirected to another.
That information also needs to be encoded as RDF (“Resource Description Framework”). The RDF document you receive from a Linked Data server consists of a set of statements (called “triples”) about various things,including the original “resource” which your original URI identified, but usually also other things as well. Those statements assign various properties to the resources, and also link them to other resources. Since those other resources are also identified by URIs, you can follow those links and retrieve information about those related resources, and resources that are related to them, and so on.
Linked Data URIs as proxies for Museum Victoria identifiers
So one of the main tasks of the Linked Data proxy is to take any identifiers which it retrieves from the Museum Victoria API, and convert them into full HTTP URIs. That’s pretty easy; it’s just a matter of adding a prefix like “http://example/something/something/”. When the proxy receives a request for one of those URIs, it has to be able to turn it back into the form that Museum Victoria’s API uses. That basically involves trimming the prefix back off. Because many of the things identified in the Museum’s API are not information resources (many are physical objects), the proxy makes up two different URIs, one to denote the thing itself, and one to refer to the information about the thing.
The conceptual model (“ontology”)
The job of the proxy is to publish the data in a standard Linked Data vocabulary. There was an obvious choice here; the well-known museum ontology (and ISO standard) with the endearing name “CIDOC-CRM”. This is the Conceptual Reference Model produced by the International Committee for Documentation (CIDOC) of the International Council of Museums. This abstract model is published as an OWL ontology (a form that can be directly used in a Linked Data system) by a joint working group of computer scientists and museologists in Germany.
This Conceptual Reference Model defines terms for things such as physical objects, names, types, documents, and images, and also for relationships such as “being documented in”, or “having a type”, or “being an image of”. The proxy’s job is to translate the terminology used in Museum Victoria’s API into the terms defined in the CIDOC-CRM. Unsurprisingly, much of that translation is pretty easy, because there are long-standing principles in the museum world about how to organise collection information, and both the Museum Victoria API and the CIDOC-CRM are aligned to those principles.
As it happened I already knew the CIDOC-CRM model pretty well, which was one reason why a museum API was an attractive subject for this exercise.
Progress and prospects
At this stage I haven’t yet translated all the information which the Museum’s API provides; most of the details are still simply ignored. But already the translation does include titles and types, as well as descriptions, and many of the important relationships between resources (it wouldn’t be Linked Data without links!). I still want to flesh out the translation some more, to include more of the detailed information which the Museum’s API makes available.
This exercise was a test of my XProc-Z software, and of the general approach of using a proxy to publish Linked Data. Although the result is not yet a complete representation of the Museum’s API, I think it has at least proved the practicality of the approach.
At present my Linked Data service produces RDF in XML format only. There are many other ways that the RDF can be expressed, such as e.g. JSON-LD, and there are even ways to embed the RDF in HTML, which makes it easier for a human to read. But I’ve left that part of the project for now; it’s a very distinct part that will plug in quite easily, and in the meantime there are other pieces of software available that can do that part of the job.
See the demo
The proxy software itself is running here on my website conaltuohy.com, but for ease of viewing it’s more convenient to access it through another proxy which converts the Linked Data into an HTML view.
Here is an HTML view of a Linked Data resource which is a timber cabinet for storing computer software for an ancient computer: http://conaltuohy.com/xproc-z/museum-victoria/resource/items/1411018. Here is the same Linked Data resource description as raw RDF/XML: http://conaltuohy.com/xproc-z/museum-victoria/data/items/1411018 — note how, if you follow this link, the URL in your browser’s address bar changes as the Linked Data server redirects you from the identifier for the cabinet itself, to an identifier for a set of data about the cabinet.
The code
The source code for the proxy is available in the XProc-Z GitHub repository: I’ve packaged the Museum Victoria Linked Data service as one of XProc-Z’s example apps. The code is contained in two files:
- museum-victoria.xpl which is a pipeline written in the XProc language, which deals with receiving and sending HTTP messages, and converting JSON into XML, and
- museum-victoria-json-to-rdf.xsl, which is a stylesheet written in the XSLT language, which performs the translation between Museum Victoria’s vocabulary and the CIDOC-CRM vocabulary.
Hey Conal,
That’s a smart convertor but the CRM modeling leaves a lot to be desired.
P3_has_note should be a simple literal, not a node; p70_documents is spelt in lowercase; P130_shows_features_of is for items that are copies of each other not just “generally related”, etc etc etc.
If there’s interest I could review this. I got lots of CRM experience, see https://github.com/usc-isi-i2/saam-lod/wiki/SAAM-LOD-Review and links there. And now mapping Getty CONA.
Thanks very much Vladimir!
The primary focus of this experimental work is to test out the network architecture (i.e. a transforming proxy) rather than to produce a “production quality” expression of Museum Victoria’s dataset. However, I do intend to continue revising the modelling, mostly to incorporate more of the Museum Victoria data in the RDF representation, and of course to refine the modelling I’ve done so far and correct any errors. So I’m very grateful for your comments on the CRM mapping and for any further ideas you might care to contribute, whether by commenting here or by logging an issue or pull request on the GitHub repository. I’ve taken some useful advice from Richard Light on the CRM-sig mailing list too, and I expect to be asking for more as I go.
I’ve already made a change to fix the typo in
P70_documentsand to simplify the expression ofP3_has_note.EDIT: I’ve added a couple of subproperties of
P3_has_noteto accommodate the various “note-like” properties in the MV data, and I suspect I will need to add several more as I go.Your comment about the
P130_shows_features_ofpredicate is not such a straightforward issue, though. My reading of the scope note is that it may validly be applied not only to scenarios involving copying, but also to cases in which items have similar features without one necessarily being a copy of another. Perhaps I’m being overly generous there?In any case, this is how I’ve chosen to provisionally represent a relation which the Museum Victoria API expresses only with extreme generality: items which are linked to other items via a JSON array called
relatedItems. What is the nature of that relatedness? I don’t actually know, but to find out I will either have to wait for MV to better document the semantics of their JSON, or by spending more time on actual empirical investigation of how that relation is used in their dataset. My initial hypothesis was that “relatedItems” would share some feature in common, and in fact I know this is true in some cases. However it’s also quite possible that the relatedness between two items may not be due to an essential similarity, but rather because they are parts of some larger whole, or have similar provenance, or are contemporaneous, or for any number of other contextual reasons. It may well end up that therelatedItemsrelation is too general to represent with any of the CRM properties, and I’ll have to resort to some much more general property from another ontology.very nice article and want to share a tool which helps your readers http://jsonformatter.org for json lover.
Thanks Iris! I’ve also used a Firefox extension http://jsonview.com/ for viewing JSON in the browser. There are some similar plugins available for Chrome, too: https://chrome.google.com/webstore/search/json?hl=en-GB