Notes for my Open Repositories 2017 conference presentation. I will edit this post later to flesh it out into a proper blog post.
Follow along at: conaltuohy.com/blog/analysis-policy-online/
Continue reading Analysis & Policy Online
Tag: oai-pmh
Visualizing Government Archives through Linked Data
Tonight I’m knocking back a gin and tonic to celebrate finishing a piece of software development for my client the Public Record Office Victoria; the archives of the government of the Australian state of Victoria.
The work, which will go live in a couple of weeks, was an update to a browser-based visualization tool which we first set up last year. In response to user testing, we made some changes to improve the visualization’s usability. It certainly looks a lot clearer than it did, and the addition of some online help makes it a bit more accessible for first-time users.
The visualization now looks like this (here showing the entire dataset, unfiltered, which is not actually that useful, though it is quite pretty):
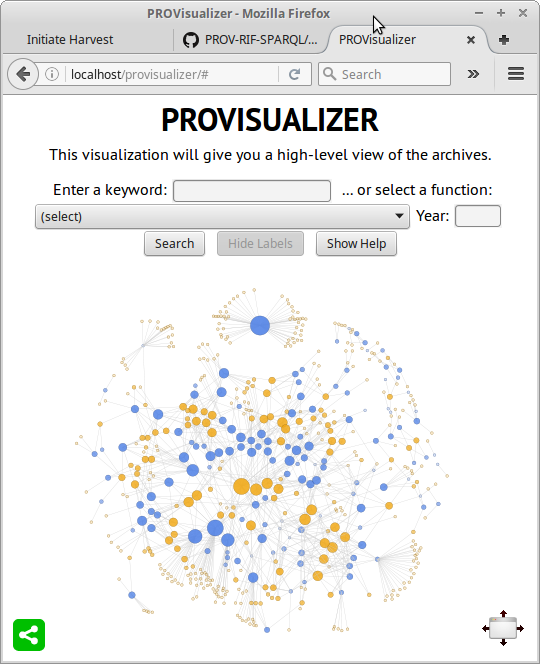
Continue reading Visualizing Government Archives through Linked Data
Public OAI-PMH repository for Papers Past
I have deployed a publicly available service to provide access in bulk to newspaper articles from Papers Past — the National Library of New Zealand’s online collection of historical newspapers — via the DigitalNZ API.
The service allows access to newspaper articles in bulk (up to a maximum of 5000 articles), using OAI-PMH harvesting software. To gain access to the collection, point your OAI-PMH harvester to the repository with this URI:
https://papers-past-oai-pmh.herokuapp.com/ Continue reading Public OAI-PMH repository for Papers Past
How to download bulk newspaper articles from Papers Past
Anyone interested in New Zealand history should already know about the amazing Papers Past website provided by the National Library of New Zealand, where you can read search and browse millions of historical newspaper articles and advertisements from New Zealand.
You may also know about Digital New Zealand, which provides a central point for access to New Zealand’s digital culture.
This post is about using Digital NZ and Papers Past to get access, in bulk, to newspaper articles, in a form which is then open to being “crunched” with sophisticated “data mining” software, able to automatically discover patterns in the articles. In my earlier post How to download bulk newspaper articles from Trove, I wrote:
Some researchers want to go beyond merely using computers to help them find newspaper articles to read (what librarians call “resource discovery”); researchers also want to use computers to help them read those articles.
To use that kind of “data mining” software, you first need to have direct access to your data, and that can mean having to download thousands and thousands of articles. It’s not at all obvious how to do that, but in fact it can be made quite easy, as I will show.
First, though, a brisk stroll down memory lane…
Continue reading How to download bulk newspaper articles from Papers Past
How to download bulk newspaper articles from Trove
Before the internet, before TV, before radio, newspapers ruled. There were literally hundreds of newspapers, published in towns and cities all over Australia, and they carried the daily life of Australians in all its petty detail. For historians, newspapers were a diamond mine; the information content was hugely valuable; the hard part was all the digging you had to do. It used to be that you would have to go to a library where a newspaper collection was held, and search manually through text on paper or microfiche. You had to be prepared to put in a lot of hard slog.
But then everything changed. A humanities researcher once told me that for Australian researchers, the National Library’s of Australia’s “Trove” newspaper archive marked a radical break: “There was a Before Trove, and an After Trove”.
Continue reading How to download bulk newspaper articles from Trove